While the release of GPT-4 and other LLMs has taken the world by storm, it is important to recognize that fundamental limitations faced by the AI models we use today. The benchmarks and evaluations utilized to prove the cognitive capabilities of these models are flawed in their own right, and even if one is to believe them, suggest fundamental power laws suggest that we are probably further from generalized, and especially superintelligence, than what we may have been led to believe.
The release of GPT-3 to the public will without a doubt go down as one of the most monumental events in the interconnected histories of technology, science, business, and philosophical thought. Humanity was, without warning, presented with a strange reflection, a simulrca that presented itself like a human but was controlled by bits rather than flesh, powered by electricity rather than food. AI, once rooted mainly in the dreams of academics and 1960s science-fiction authors, was now in the hands of all. With opportunity came seekers, and soon enough, the technologist equivalent of the gold-rush began, with 100s of new models being released every week, both in an open-source and private manner.
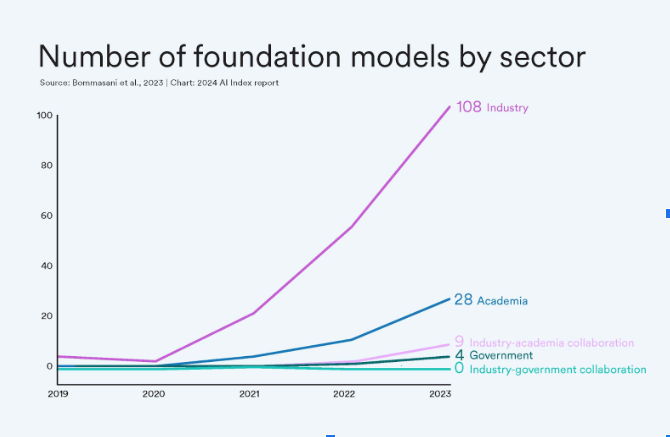
Note the massive growth in foundational models produced by academia and industry, compared to the government, in this graph from a report published by Stanford
This new wave has prompted many an innovator, scientist, and thinker to proclaim that we are on the verge of AI Doom, a nightmare scenario in which humanity has to submit to its mechanical overlords due to our own irresponsibility and a lack of checks on the development of artificial intelligence. However, the reality today, outside from the miniaturized bubble of “tech”, suggests something else entirely, that AI, like the crypto bubble before it, is just that: a set of promising and innovative technologies that while having an extremely high potential, are nowhere close to fundamentally changing the human condition. AGI, or AI that reasonably perform at the cognitive level of an advanced human, is still far away, and more, not less, resources should be poured in making sure that we get there.
Numbers can lie: the reality of today's evaluation techniques
The primary evidence that most “AGI is coming soon” proponents point to are the progressively higher scores achieved by frontier foundational models on popular benchmarks: in the first chapter of Situational Awareness, Aschenberner cites the performance of GPT-4 on normalized educational aptitude tests, and FM-specific evaluation tests such as the MATH benchmark, a collection of medium to challenging mathematics questions with definitive numerical solution, as compared to its year-old predecessors.
Left: example of a question on the MATH Benchmark. Right: A question on MMLU, a comprehensive evaluation for LLMs.
However, there is a hidden problem with the majority of evaluations being utilized to prove the capabilities of most models used today: contamination. No, this is not a malignant virus or bacteria, but rather a phenomenon that describes how most evaluations end up inadvertently becoming a part of the very datasets used to train the models themselves, leading to those models overfitting on them and “memorizing” the answers to those evaluations. To visualize this, imagine that you are a high school student that has been gifted with an expanded hippocampus that can essentially allow you to memorize an unlimited amount of information at the cost of hampered reasoning ability. You can probably see how this allows you to essentially ace any test, as long as you have seen the questions and answers previously, but will result in you being stuck anytime you see a new question that requires you to apply the knowledge you have memorized. This is exactly what is happening with modern evaluations: the newest LLMs, which claim to be as prolific of a writer as Shakesphere while simultaneously being as mathematically inclined as Issac Newton, don’t hold up when presented with questions that were not public when they were trained.
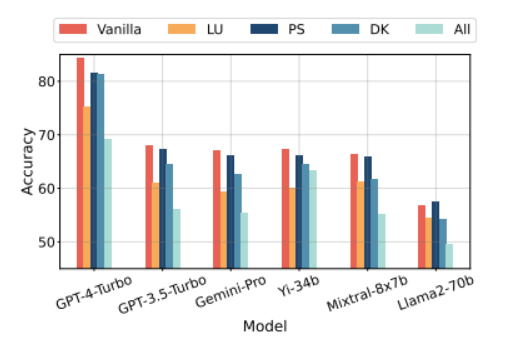
Popular LLM performance on unaltered questions from MMLU (red) vs altered questions (everything else). Graph from the following published paper.
These results should not be astounding if you have interacted with LLMs in any meaningful way: while they are extremely useful at performing rote, computational tasks, they falter when confronted with something more complex. LLMs are extremely prone to hallucination, and often make critical mistakes. It is important to note that these phenomena are not inherently malicious; as Aschenberner himself notes, the proliferation of new models has far outpaced the creation of new benchmarks. Combine that with the fact that most large models are often training on a large subset of the entire internet, and you can see why most of the public evaluations and tests out there are inadvertently being memorized by the newest foundational models.
Perhaps the best academic example of the progress, or lack thereof, that foundational models have made toward achieving anything even close to simulating cognition can be seen in the Abstract Reasoning Corpus (ARC), which is an evaluation for AI models designed to measure reasoning and complex skill acquisition developed by François Chollet, a researcher at Google. ARC works by challenging models to solve previously unknown tasks based on known examples, similar to an IQ test, rather than attempting to measure generalizable knowledge that may easily be acquirable. Most notably, contemporary models score far below human-level performance on ARC, indicating that while they may be able to perform rote tasks and operations at an extremely high level, they are still far behind the average human when it comes to reasoning and deriving solutions to new problems based on pattern recognition.
The AI “boom” is not a boom, but rather a well-orchestrated explosion
The central claim that most proponents of the “AGI soon” camp point rest their heads on is the progress made, both in terms of powerful hardware being readily made available to the public and highly efficient algorithms drastically reducing the learning speeds for foundational models, in the past couple of years. However, it is important to take a step back and deconstruct the phenomena that are TPUs and compute efficiencies. Moore’s Law is still very intact (and might even to some extent be dead) despite what you might have been led to believe by the accel mob on Twitter.
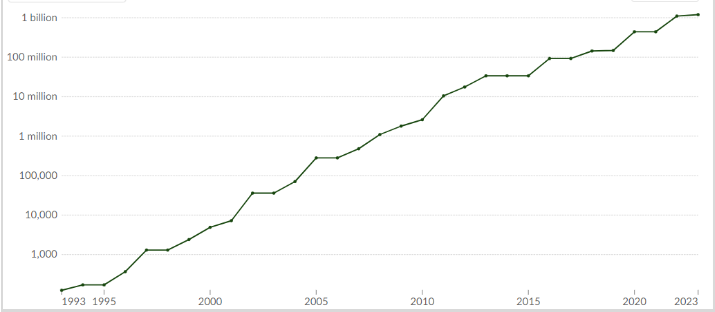
Graph from our world in data showcasing the growth in computational capacity of supercomputers, expressed in GigaFlops, over time
The recent growth that we saw for AI, after all, was not the product of some sudden, innovative hardware or algorithmic breakthrough, but rather the result of years of research, development, and experimentation. Indeed, capital inflow and the external attention given to generative AI has grown far beyond what one might have expected in recent years, but the capabilities of these models should not surprise anyone who was aware of the developments happening in the space pre-2022, especially someone who may have been a part of the San Francisco AI community that Aschenberner himself cites.
Now, you might be wondering: Isn’t that the entire point? That we need to accelerate the development of AGI/ASI? And your claim will be right, but partially. The underlying crux of the arguments presented by Aschenberner and others who believe in an AGI-soon timeline (note that this includes both “doomers” and “accelrationists”) is that AGI is inevitable, and that we (the collective “we” meaning society, the US government, etc depending on who is making the argument) should be pricing the eventual development of AI into our lives now in order to get ready. However, at the current pace, this is likely not true. While improvements in algorithmic efficiency and hardware have certainly contributed to the development of GPT-4 and others of its ilk, the major contribution was funding: massive investments enabled frontier labs and established organizations such as Google to procure the hardware and talent needed to train monolith-sized models we see today. However, there is an upper limit to such improvements: for example, GPT-4, despite being significantly more aligned than its predecessor, was still as, and in some cases, even more, prone to hallucination.
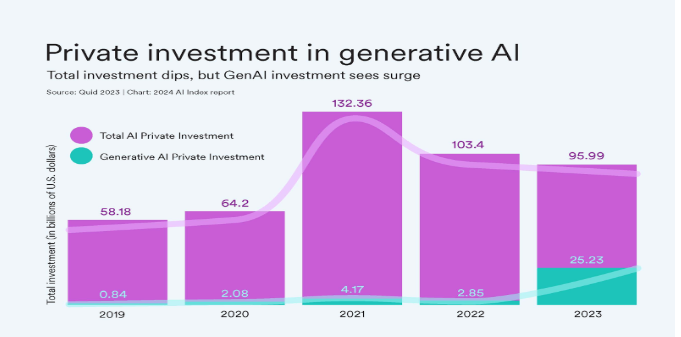
It is also important to note that the results of invested capital in frontier technologies often take years to manifest; indeed, the largest institutional investments in AI were during the 2020-2021 pandemic period, and are actually coming back down in recent years. Open-source AI has a funding problem, with many academic labs and open-source projects falling behind larger companies. Assuming that the trend that we saw in 2022 and 2023, which was really the end of result of a multi-year R&D effort and a historic influx of capital, will not only continue but accelerate in an exponential manner is certainly a stretch.
Graph from Stanford Report showcasing investment in Gen-AI
It is important to note that the purpose of this section, and really the entire broader series that it is a part of, is not to present a gloomy-outlook on the current state of AI. Instead, it is to highlight the realities of how far we are from achieving AGI, and to implore the public collective to continue to move, tinker, and experiment rather than assuming that AGI is an inevitability. The current reality is that progress in fundamental compute has slowed down, not increased, and that algorithmic improvements, despite improving the efficiency with which new models can be trained and developed, have not resulted in significantly increased cognitive performance for the publicly-available models that we use today.